



🚨 WinRAR's Critical Path Traversal Vulnerability Continues to Be Exploited by Hackers: You Must Upgrade Immediately!
In August 2025, renowned cybersecurity company ESET released a security report indicating a critical path traversal vulnerability (CVE-2025-8088) in the popular compression manager WinRAR. This vulnerability allows hackers to initialize access on a victim's system and deliver various malicious payloads.
In August 2025, renowned cybersecurity company ESET released a security report indicating a critical path traversal vulnerability (CVE-2025-8088) in the popular compression manager WinRAR. This vulnerability allows hackers to initialize access on a victim's system and deliver various malicious payloads.
Good News: Vulnerability is Patched!
Fortunately, thanks to ESET's proactive and responsible notification of this vulnerability, the WinRAR development team fixed the issue in version v7.13 released on July 30, 2025. Therefore, if you are using WinRAR v7.13 or later, you are not affected by this vulnerability.
Why is this vulnerability so dangerous?
Although the vulnerability has been patched, WinRAR lacks an automatic update function, resulting in a large number of users still using older versions. These outdated software versions have become a continuous target for hackers.
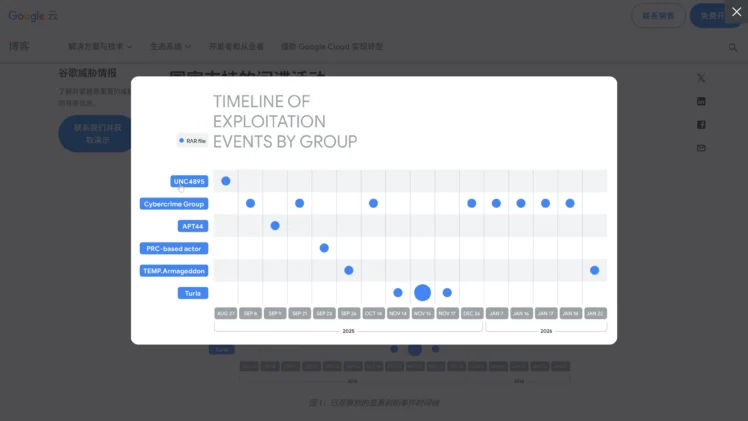
📊 Google Threat Intelligence Report
Attack Timeline and Scope
A recent report from Google's Threat Intelligence team indicates:
- This attack on WinRAR began as early as July 18, 2025, and has not stopped since
- The attackers include both state-sponsored espionage organizations and low-level cybercriminals driven by financial interests
How is the attack carried out?
Hacker attacks typically employ the following chain:
- Malicious files are hidden within compressed archives, for example, using Alternate Data Streaming (ADS) technology
- These archives are disguised as normal files, containing decoy content and a hidden malicious payload
- The vulnerability is triggered when a user opens or extracts these archives using WinRAR
- WinRAR, during path traversal, extracts the hidden malicious payload to an arbitrary location
- The generated malicious files typically include LINK, HTA, BAT, CMD, or other script files
- These script files are written to the system's startup directory or critical locations and execute upon system startup when the user logs in
Identified Hacker Groups
Google's threat intelligence team observed several active hacking groups, including but not limited to:
- UNC4895
- APT44
- Turla
In addition, some hacking groups with financial interests are exploiting this vulnerability to:
- Distribute malware
- Steal sensitive user information
- Distribute backdoor programs controlled by Telegram bots
- Install malicious browser extensions to steal banking information
A more worrying trend: Commoditization of exploits
The report notes that these hackers appear to obtain exploits from specialized vulnerability vendors. For example:
- A vendor codenamed ZeroPlayer advertised an exploit targeting WinRAR in July 2025
Google researchers commented that this commoditization of exploit development reflects a trend in the cyberattack lifecycle: the commoditization of exploits lowers the barrier and complexity for attackers to launch attacks, making any unpatched system vulnerable to attack in a short period of time.
What should you do?
In the face of ongoing attacks, do not take chances:
✅ Upgrade WinRAR Immediately
Visit the official latest version download page: Click here
Download and install WinRAR v7.13 or later.
✅ Check Your Current Version
Open WinRAR, click "Help → About," and confirm that the version number is 7.13 or later.
❌ Avoid Risky Versions
Do not use old versions or portable versions from unknown sources. These versions usually do not include official content.
Critical security update • Protects against CVE-2025-8088 • Immediate upgrade required • Free download































_a_use_back_this_image-812026.webp)